

ETL vs ELT
La trampa de la pasión, y cómo tener tu propio S3 (en tu cara AWS)

Lo que vas a ver en esta edición:
Dos enfoques súper importantes para construir pipelines de datos
“Sigue tu pasión”…¿es realmente un buen consejo?
No gastes dinero innecesariamente si estás desarrollando con Amazon S3
🧠 El Núcleo
ETL vs ELT
En la edición anterior, aprendimos que los Data Engineers construimos pipelines para automatizar el movimiento y procesamiento de datos de manera eficiente, escalable, y segura.
Lo que nos toca ver hoy son dos maneras (aunque no las únicas) para construir dichos sistemas. Te las presento: ETL y ELT, dos enfoques o patrones distintos —aunque complementarios— para mover datos desde su origen hasta su destino.
¿Qué son?
ETL y ELT son patrones de diseño de pipelines de datos, es decir, son una secuencia o forma estructurada de definir el flujo que siguen los datos, desde que se extraen, hasta que transforman y almacenan. Arranquemos con ETL, el que se suele utilizar con más frecuencia (aunque parece que la tendencia está empezando a ir más por ELT).
ETL — Extract, Transform, Load
ETL es el framework más antiguo y aún el más común para diseñar pipelines de datos, desgranando el flujo de datos en tres pasos secuenciales:
Extract - extracción de datos desde un sistema fuente (source system, término que conviene anotar), como lo puede ser una API, una base de datos, un archivo Excel generado por algún sistema de reportes, etc.
Transform - transformar los datos extraídos, ya sea mediante:
cambiar los tipos de datos (de número a texto)
su formato (como suele suceder con las fechas)
los nombres de los campos
aplicar lógica de negocio
eliminar elementos no deseados (como cuando te viene un precio con el signo $ y vos querés guardar números, no texto)
agregar metadatos (otro término importante) para enriquecer a los datos originales y darles contexto, etc.
o simplemente hacerlos coherentes para análisis posterior
esto lo vimos en la edición anterior, ¿te acordás?
Load - cargar los datos en una base de datos destino, un warehouse, otro archivo Excel o cualquier otro activo de datos que el usuario final de estos datos utilice
Este enfoque se usa mucho cuando:
Las transformaciones son pesadas y requieren motores externos (Python, Spark, etc.).
El destino no está preparado para hacer cómputo intensivo (por ejemplo, un Data Warehouse clásico).
Querés controlar toda la lógica de transformación fuera del sistema final.

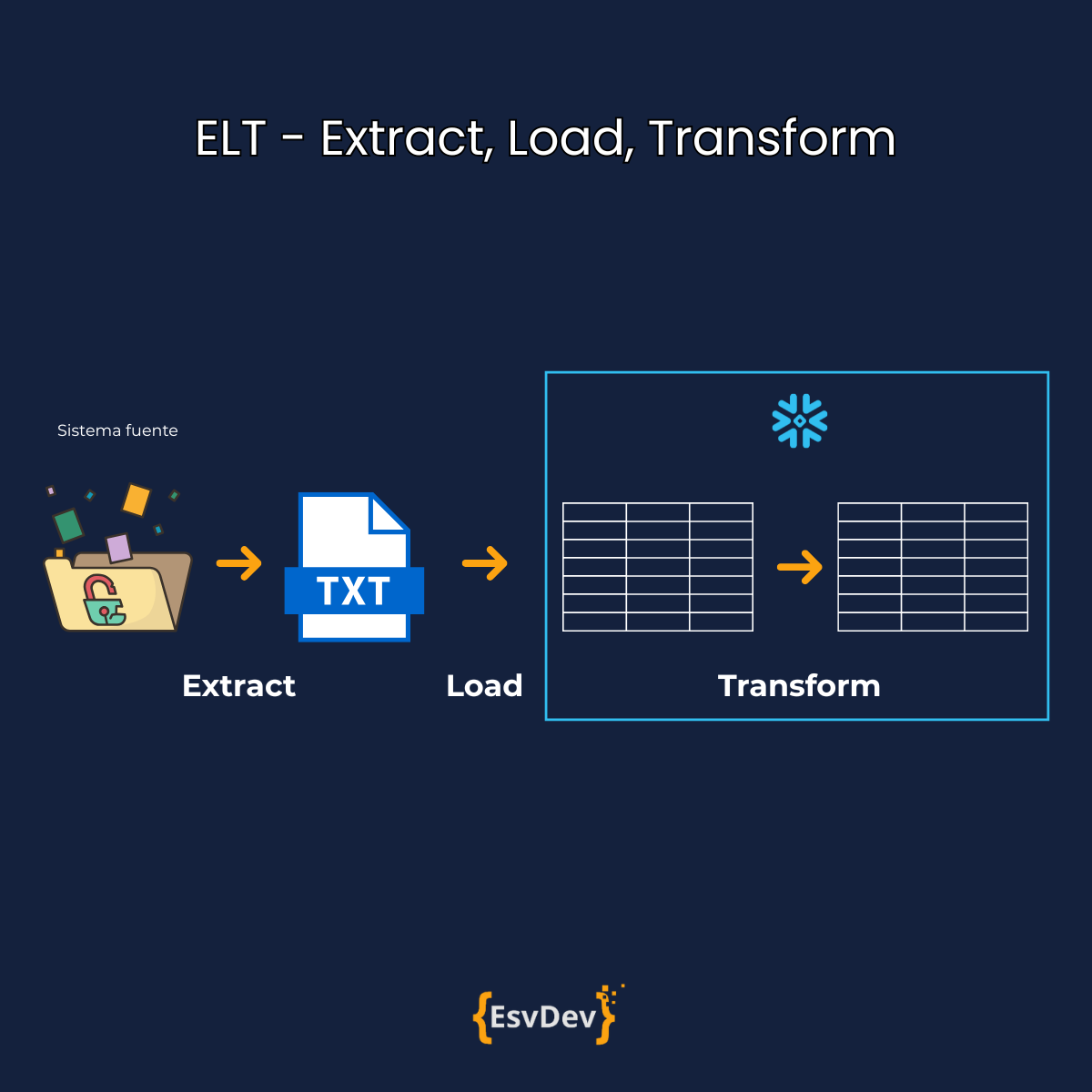
ELT — Extract, Load, Transform
En los últimos años, con la aparición de data warehouses modernos (como Snowflake, BigQuery o Redshift), el orden de las letras cambió… y también la forma de trabajar.
En el enfoque ELT, primero se:
Extraen los datos desde la fuente,
Cargan tal cual (en crudo) en el warehouse,
Y Transforman directamente dentro del warehouse, usualmente con SQL.
La idea es aprovechar el poder de cómputo y la escalabilidad del warehouse para transformar los datos una vez cargados.
Este patrón es ideal cuando:
El warehouse es potente y soporta grandes volúmenes.
Las transformaciones están mayormente basadas en SQL.
Se quiere guardar el los datos en crudo (también llamado raw data o capa raw) sin modificar, para poder re-procesarlo o auditarlo después.
¿Cuál patrón utilizar?
Si te estás haciendo esta pregunta, dejame decirte que es perfectamente válida. ¿En qué casos cargo todo primero y luego transformo (ELT)? ¿O cuándo me conviene irme por el clásico de extraer, transformar y servir los datos al usuario final (ETL)? ¿O es que uno de los dos patrones es definitivamente mejor en general? Como me gusta decir…depende.
No existe bala de plata, no hay uno mejor que el otro per se, y es más, hasta puede suceder (y sucede) que un mismo proyecto requiera una combinación de ambos enfoques, y de hecho, en muchos proyectos se combinan ambos.
Por ejemplo:
Extraés datos crudos (E),
Los transformás con Spark (T),
Los cargás en un warehouse (L),
Y luego hacés transformaciones adicionales con SQL (T).
¿ETLT? Podríamos decir que sí 😄
Lo importante es que tu pipeline tenga claridad, trazabilidad y eficiencia, sin importar la etiqueta.
Lo que quiero que te lleves
ETL → Extract → Transform → Load → los datos se limpian antes de almacenarse.
ELT → Extract → Load → Transform → los datos se cargan primero y se transforman dentro del warehouse.
Ninguno es “mejor”: todo depende del contexto, los recursos y los objetivos del proyecto.
Y sí, incluso puede haber pipelines que sean solo EL (sin transformación), cuando el destino ya está preparado para consumir los datos en bruto.
No existe una bala de plata que solucione y abarque todos los casos. ETL no es mejor que ELT per se, y lo inverso también es cierto. Todo depende de las necesidades del negocio, las fechas límite y las limitaciones técnicas/monetarias.
💭 Debug Mental
La Trampa de la Pasión
Lo habrás escuchado mil veces: “Encontrá tu pasión y seguila”, “Si sigues tu pasión, la felicidad viene a continuación”. Y estoy seguro de que debe haber muchas formas más de decir lo mismo.
El punto es que…¿qué significa “encontrar la pasión”? ¿Es acaso algo accionable? Para la mayoría de personas, está complicado. ¿Qué es nuestra pasión? ¿Vos sabés cuál es la tuya? E incluso si la encontraste, ¿tenés un plan para “seguirla”?
¿Será que acaso este consejo hace más mal que bien?

En una investigación de 2012 liderada por Robert J. Vallerand titulada “El papel de la pasión en el bienestar psicológico sostenible”, se presentó el Modelo Dualista de la Pasión (MDP), que distingue entre dos tipos de pasiones, la pasión armoniosa y la pasión obsesiva:
Armoniosa: cuando se elige libremente una actividad que te aporta significado, que sentís que te llena como individuo e integrás esa actividad en tu vida, sin que la actividad te controle
Obsesiva: cuando tu identidad depende de cierta actividad, al punto tal de que se siente como una carga a la que no podés renunciar
Y acá viene lo interesante: la opinión principal del artículo es que el simple hecho de dedicarse a una actividad que nos apasiona no garantiza resultados positivos; lo que realmente importa es el tipo de pasión que se tiene.
Las personas con pasiones armoniosas reportaron mayores niveles de alegría, concentración o foco. En cambio, quienes perseguian una pasión obsesiva experimentaron estrés, conflictos emocionales, y, ojo con esto, burnout.
En el artículo se previene sobre el famoso consejo que mencioné al principio, de “seguir (o encontrar) tu pasión”. Este consejo implica que la pasión es algo con lo que se nace, o que a lo mejor se descubre de forma instantánea, ahí formada y lista para que la sigas.
Creer esto generalmente conduce a mucha frustración. Y claro, intentás algo, no sentís esa “chispa” (que supuestamente deberías sentir) y entonces…lo abandonás ante la primera señal de dificultad.
Los investigadores argumentan que la alegría proviene de construir una relación significativa con una actividad, sin esperar que dicha actividad produzca felicidad instantáneamente.
¿Y si resulta que la pasión no es algo que se encuentre? A lo mejor la pasión puede venir como resultado de algo más.
Según un autor que descubrí hace poco, Scott Galloway, seguir nuestros talentos puede conducir a la pasión. Pasión que proviene del esfuerzo, la maestría y la conexión.
Opiniones hay muchas, pero yo estoy cada vez más convencido de que la pasión puede construirse. Pero hay que esforzarse y ser consistente, a la vez que exploramos actividades que nos den una sensación de plenitud, nos llenen como personas y también se nos dé bien realizar.
¿Difícil? Sí. ¿Posible? También.
📚 Datazo
Tené tu propio S3 en tu PC
Hoy te traigo una herramienta muy copada si trabajás con Amazon S3 frecuentemente.
¿Te imaginás contar con tu propio S3 de manera local y totalmente gratis y sin depender de la nube? Eso es lo lindo de MinIo.
¿Qué es MinIo?
MinIO es una herramienta open source que emula el servicio de almacenamiento de objetos de AWS (Amazon S3).
En otras palabras, podés crear y administrar tus propios buckets, subir y descargar archivos, generar presigned URLs y mucho más… sin salir de tu máquina.
Y lo mejor: habla el mismo idioma que S3.
Eso significa que si en tu código usás el SDK de AWS (por ejemplo, boto3 en Python), prácticamente no necesitás cambiar nada para usar MinIO en lugar del S3 real. Mirá:
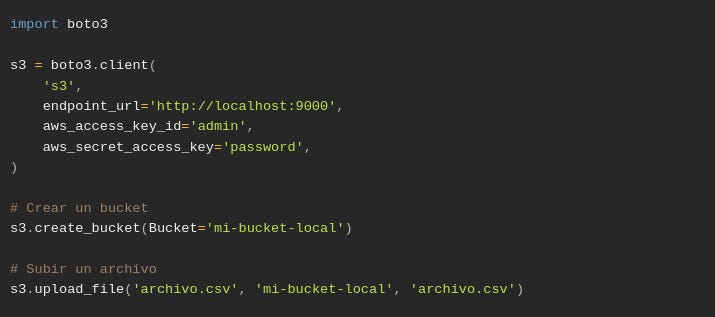
Listo. Tenés un sandbox de S3 completamente funcional para tus desarrollos o experimentos.
¿Por qué usarlo?
Acá te van algunas razones por las que vale la pena tenerlo en tu toolkit 👇
Entorno local y sin costo: perfecto para practicar o testear sin preocuparte por gastos en AWS.
Aislamiento: podés experimentar sin afectar buckets reales o datos sensibles.
Velocidad: al correr localmente, las pruebas son mucho más rápidas que subir y bajar archivos desde la nube.
Integración con herramientas de Data Engineering: MinIO se lleva de maravilla con frameworks como Airflow, Spark o Prefect, que suelen interactuar con almacenamiento tipo S3.
¿Cómo instalarlo?
Existen varias maneras, pero la que te recomiendo (y de hecho yo mismo uso) es su versión contenedor de Docker. En este post de mi autoría vas a encontrar un paso a paso bien preciso y detallado para que tengas MinIo instalado en tu máquina, ¡con interfaz gráfica y todo!
En resumen
MinIO es una herramienta genial para quienes:
Quieren practicar o testear integraciones con S3 sin depender de AWS.
Necesitan un entorno local rápido y seguro.
Buscan aprender sobre almacenamiento de objetos y su arquitectura.
En definitiva, es un gran aliado para Data Engineers y Developers que trabajan en entornos híbridos o con pipelines complejos.
Resumen nivel 5

Lo que quiero que te lleves de esta edición es:
ETL y ELT son dos patrones de diseño muy utilizados para construir pipelines de datos. Aprendé sus bases, pero sobre todo, el propósito detrás de cada uno. Son herramientas después de todo.
A lo mejor no hay que encontrar y seguir tu pasión. A lo mejor simplemente se trata elegir una actividad significativa, comprometerse y construir una relación sana con esa actividad. Puede que ahí nazca una pasión armoniosa, esa pasión que de verdad pueda nutrir tu alma.
MinIo es una hermosa herramienta para desarrollar con S3 de manera veloz, sin mayores consecuencias y gratarola.